Les syndicats ont généralement une position prudente et critique.

Sécurité de l'emploi : Les syndicats craignent que l'IA ne remplace des emplois, entraînant des pertes d'emplois et une augmentation du chômage.
Conditions de travail : Ils sont préoccupés par les impacts potentiels de l'IA sur les conditions de travail, notamment en termes de surveillance accrue et de pression sur les employés.
Formation et compétences : Les syndicats insistent sur la nécessité de former les travailleurs aux nouvelles compétences requises par l'IA pour éviter l'exclusion technologique.
Éthique et transparence : Ils demandent une réglementation stricte pour garantir que l'IA soit utilisée de manière éthique et transparente, afin de protéger les droits des travailleurs.
En résumé, les syndicats soutiennent une adoption responsable et équitable de l'IA, en mettant l'accent sur la protection des travailleurs et la promotion de l'équité sociale.

Rentrée 2024 : offensives sur l'IA dans l'éducation
15 octobre 2024. Deux ans après le lancement des intelligences artificielles génératives grand public, l'école semble ensorcelée.
« À la rentrée 2024 on ne trouve pas un plan académique de formation sans proposition pour « enseigner et apprendre à l'ère de l'IA ». Au sein de la DNE (Direction du numérique pour l'éducation), une Communauté de Réflexion en Éducation sur l'Intelligence Artificielle (CREIA) « a pour ambition de mettre l'innovation et l'intelligence artificielle (IA) au coeur des pratiques pédagogiques et des réflexions en éducation. »
Cette obsession institutionnelle se lit aussi dans la lettre de saisine du Conseil Supérieur des Programmes de mars 2024 pour la refonte des programmes du Cycle 1 au Cycle 4. N. Belloubet appelle à « créer une culture de l'IA » à tous les niveaux et dans toutes les disciplines (lire ici notre analyse de l'ensemble des lettres de saisine) !
Enfin, Clara Chappaz, issue du monde des startups, est nommée « secrétaire d'État chargée de l'Intelligence artificielle et du numérique » auprès du Ministère de l'enseignement supérieur et de la recherche. Ce portefeuille et son rattachement au MESR sont deux nouveautés, puisque les personnes ayant précédemment occupé la fonction dépendaient de Bercy, et que l'IA n'était pas mise en avant particulièrement.

Pour le SNES-FSU,
les programmes et la formation des personnels doivent introduire une réflexion critique sur les usages des IA et leurs conséquences. Pour cela, des recherches sur l'impact des IA sur le travail des élèves et des personnels sont à mener d'urgence, à l'écart du lobbying des acteurs ayant des intérêts lucratifs dans ce domaine. Lors du Congrès de La Rochelle de 2024, le SNES-FSU a actualisé et approfondi ses mandats pour un « numérique maîtrisé » : https://www.epi.asso.fr/revue/lu/l2411d.htm
https://www.snes.edu/article/un-numerique-maitrise-les-mandats-du-snes-fsu/
https://www.snes.edu/article/rentree-2024-offensives-sur-lia-dans-leducation/
Pour le SNES-FSU, les programmes et la formation des personnels doivent introduire une réflexion critique sur les usages des IA et leurs conséquences. Pour cela, des recherches sur l’impact des IA sur le travail des élèves et des personnels sont à mener d’urgence, à l’écart du lobbying des acteurs ayant des intérêts lucratifs dans ce domaine. Lors du Congrès de La Rochelle de 2024, le SNES-FSU a actualisé et approfondi ses mandats pour un “numérique maîtrisé”. ceci en fin 2024
L’IA fait sa rentrée !
Pour répondre aux enjeux et usages pédagogiques des services numériques utilisant l’intelligence artificielle en éducation, la Direction du numérique pour l'Éducation (DNE) propose un webinaire le 30 août 2024, de 13h30 à 14h30.
Seront présentés les enjeux, les perspectives 2024-2025 et des exemples de pratiques pédagogiques dans le cadre de la "CREIA" (Communauté de réflexion en éducation sur l'IA animée par les équipes du MENJ et celles académiques). Les chefs d'établissements et les équipes pédagogiques qui le souhaitent peuvent intégrer ce webinaire dans leur temps de pré-rentrée. Le webinaire est ouvert à tout personnel éducatif, enseignant, formateur ou cadre intéressé par le sujet de l’intelligence artificielle et de l’éducation.
>>> L’adresse de diffusion : https://videodiff.phm.education.gouv.fr/live/ia-et-education-rentree-20… https://www.ac-paris.fr/l-intelligence-artificielle-dans-l-education-130992

Document du SNES- FSU.EDU : numerique-maitrise-1.pdf
Je vais résumer ce document qui présente les positions du SNES-FSU (syndicat national des enseignements de second degré) sur plusieurs sujets clés :
1. Position sur les GRETA (formation continue des adultes) :
- Le syndicat défend leur rôle essentiel comme service public de formation
- Il demande que ces formations restent accessibles à tous
- Il s'inquiète des fusions qui dégradent les conditions de travail
- Il critique l'utilisation des fonds de mutualisation
2. Position principale sur le numérique dans l'éducation :
Le syndicat adopte une position très critique et prudente sur la numérisation de l'éducation, avec plusieurs points majeurs :
- Il dénonce une numérisation "forcée" servant des intérêts économiques (EdTech) plus que pédagogiques
- Il s'inquiète de l'impact environnemental des équipements numériques
- Il critique le manque de concertation avec les enseignants sur les outils
- Il alerte sur les risques de l'IA dans l'éducation (inégalités, dépossession du métier)
- Il défend une approche raisonnée et limitée du numérique
3. Position sur le climat scolaire :
- Le syndicat rejette l'approche managériale du ministère
- Il critique l'introduction des "compétences psychosociales" dans l'éducation
- Il défend une vision plus globale du bien-être à l'école
Mon analyse de cette position syndicale :
Les positions du SNES-FSU apparaissent cohérentes et bien argumentées. Le syndicat adopte une posture de contre-pouvoir constructif en :
1. Défendant une vision de l'éducation centrée sur l'humain plutôt que sur la technologie
2. Alertant sur les risques réels de la numérisation précipitée (environnementaux, pédagogiques, sociaux)
3. Proposant des alternatives concrètes (ex: équipements durables, logiciels libres)
Sa position sur le numérique est particulièrement pertinente car elle ne rejette pas totalement les outils numériques mais plaide pour une utilisation réfléchie et maîtrisée, au service réel des apprentissages.
Le syndicat semble avoir une approche équilibrée qui reconnaît l'importance de la modernisation tout en restant vigilant sur ses dérives potentielles, notamment la marchandisation de l'éducation et la déshumanisation de l'enseignement.
Ne prenons nous pas du retard par rapport aux autres pays ?
C'est une question légitime qui mérite une analyse nuancée :
1. Sur la réalité du "retard" :
- Il faut d'abord questionner ce qu'on appelle "retard". Si on parle d'équipement pur (nombre de tablettes, d'ordinateurs...), certains pays sont en effet plus équipés. Mais l'équipement ne garantit pas l'efficacité pédagogique.
2. Quelques exemples internationaux intéressants :
- La Finlande, souvent citée pour son excellence éducative, privilégie une approche mesurée du numérique
- La Corée du Sud, très équipée numériquement, commence à faire marche arrière sur certains aspects en constatant les effets négatifs de la surexposition aux écrans
- L'Estonie, considérée comme très avancée numériquement, a développé ses outils progressivement, en formant d'abord les enseignants
3. Les vrais enjeux ne sont peut-être pas là :
- Le "retard" le plus problématique n'est pas tant dans l'équipement que dans la formation des enseignants et la réflexion sur les usages
- La question de la fracture numérique et des inégalités sociales reste cruciale
- L'urgence environnementale impose de repenser notre rapport à la technologie
4. Une autre approche possible :
- Plutôt que de chercher à rattraper un supposé retard, ne faudrait-il pas développer un modèle français original qui :
* Privilégie la qualité plutôt que la quantité
* Met l'accent sur la formation à l'esprit critique
* Développe une vraie sobriété numérique
* Garde l'humain au centre du processus éducatif
En conclusion,
la question n'est peut-être pas tant celle du retard que celle du modèle éducatif que nous voulons construire. La course à l'équipement numérique ne doit pas faire oublier les fondamentaux de l'éducation : la transmission des savoirs, le développement de l'esprit critique et l'émancipation des élèves.
Le positionnement du SNES-FSU, qui appelle à une réflexion approfondie plutôt qu'à une numérisation précipitée, n'est donc pas nécessairement un frein au progrès, mais plutôt une invitation à repenser intelligemment notre rapport au numérique dans l'éducation.

Intelligence artificielle, curiosité et éducation Pierre-Yves Oudeye
Présentation réalisée dans le cadre du wébinaire "Usage de l'IA en éducation: retours d'expérience et perspectives" du mooc AI4T, https://inrialearninglab.github.io/ai...
Résumé: La curiosité joue un rôle clé dans les apprentissages chez les enfants, à l’école et en dehors. Elle est un des moteurs qui peut les amener à s’épanouir en prenant du plaisir à apprendre, en stimulant leur persévérance et leur créativité. Se basant sur ses travaux fondamentaux en sciences cognitives et en IA pour modéliser la curiosité chez les enfants, l’équipe Flowers à Inria travaille depuis plusieurs années à leur application dans le domaine de l’éducation. Je présente ici deux projets réalisés en collaboration entre l’équipe Flowers et l’entreprise edTech evidenceB. L’un utilise des méthodes de personnalisation des apprentissages qui stimulent la curiosité dans le cadre de l’apprentissage des maths, aujourd’hui diffusées à grande échelle dans le logiciel Adaptiv’Maths (plan P2IA du ministère de l’Education nationale) et accessible dans toutes les écoles en France (68.000 classes). L’autre où nous expérimentons les capacités très prometteuses des modèles de langage pour mettre en place des agents conversationnels qui entraînent les enfants à poser des questions curieuses. Je discute aussi des enjeux de la littératie en IA au collège et au lycée, et de plusieurs outils pédagogiques visant d’y contribuer.
Slides: Artificial Intelligence for and by Teachers https://inrialearninglab.github.io/ai4t//fr/
Liens:
Clément, B., Sauzéon, H., Roy, D., & Oudeyer, P. Y. (2024). Improved Performances and Motivation in Intelligent Tutoring Systems: Combining Machine Learning and Learner Choice. arXiv preprint arXiv:2402.01669. https://arxiv.org/abs/2402.01669
Abdelghani, R., Oudeyer, P. Y., Law, E., de Vulpillières, C., & Sauzéon, H. (2022). Conversational agents for fostering curiosity-driven learning. International Journal of Human-Computer Studies, https://hal.science/hal-03810322/docu...
Abdelghani, R., Wang, Y. H., Yuan, X., Wang, T., Lucas, P., Sauzéon, H., & Oudeyer, P. Y. (2023). Gpt-3-driven pedagogical agents to train children’s curious question-asking skills. International Journal of Artificial Intelligence in Education, 1-36. https://arxiv.org/pdf/2211.14228.pdf
Abdelghani, R., Sauzéon, H., & Oudeyer, P. Y. (2023). Generative AI in the Classroom: Can Students Remain Active Learners?. arXiv preprint arXiv:2310.03192. https://arxiv.org/abs/2310.03192
Torres-Leguet, A., Romac, C., Carta, T., Oudeyer, P-Y. (2023) ChatGPT en 5mn: une série pédagogique pour le grand public, CC-BY, https://developmentalsystems.org/chat...
Présentation des ressources AI4T¶ https://inrialearninglab.github.io/ai4t//fr/2-Project-resources/0-presentation/0-1-presentation-AI4T-resources.html
Vous trouverez ici les documents, ressources et outils qui ont contribué au projet, de sa conception à sa mise en œuvre dans le cadre de l'expérimentation AI4T.
La plupart de ces ressources sont en anglais, Italien, Allemand, Français.
Elles sont organisées en trois sections :
Section 1 - Outils d'IA (éducative) utilisés pendant la phase d'expérimentation dans les 5 pays
Section 2 - Liste des Moocs et des ressources en ligne liés à l'IA ou à l'IA et l'éducation
Section 3 - Rapports et lignes directrices relatifs à l'IA et à l'éducation

Les avancées actuelles:
* *Une priorité gouvernementale:* L'IA est devenue une priorité pour le ministère de l'Éducation nationale. La rentrée 2024 a marqué une accélération de cette tendance, avec de nombreux plans académiques proposant des formations à l'IA.
* *Des outils pédagogiques innovants:* Des plateformes numériques utilisant l'IA voient le jour, proposant des parcours d'apprentissage personnalisés et des exercices adaptés au niveau de chaque élève.
* *Une expérimentation en cours:* Le projet "MIA Seconde" vise à accompagner les élèves de seconde grâce à l'IA, mais son déploiement est encore en cours et rencontre quelques difficultés.
* *Des formations pour les enseignants:* Des initiatives comme le projet européen "AI4T" visent à former les enseignants à l'utilisation de l'IA en classe.
Les défis à relever:
* *Un manque de cadre structuré:* L'intégration de l'IA dans l'éducation se fait de manière hétérogène, sans véritable plan d'ensemble.
* *Des questions éthiques:* L'utilisation de l'IA soulève de nombreuses questions sur la protection des données, la neutralité algorithmique et l'impact sur l'autonomie des élèves.
* *Un besoin de formation approfondie:* Les enseignants ont besoin de formations solides pour utiliser efficacement les outils d'IA et accompagner leurs élèves.
En résumé:
L'IA offre de nombreuses possibilités pour améliorer l'enseignement et l'apprentissage. Cependant, pour que cette technologie soit pleinement exploitée, il est nécessaire de mettre en place un cadre clair, de former les enseignants et de réfléchir aux enjeux éthiques.
Pour en savoir plus, vous pouvez consulter ces ressources:
* *L'intelligence artificielle progresse dans l'Éducation nationale:* [https://actionetdemocratie.com/l-intelligence-artificielle-progresse-dans-l-education-nationale/](https://actionetdemocratie.com/l-intelligence-artificielle-progresse-dans-l-education-nationale/)
* *Intelligence artificielle à l'école:* [https://www.banquedesterritoires.fr/lintelligence-artificielle-lecole-entre-promesses-et-defis](https://www.banquedesterritoires.fr/lintelligence-artificielle-lecole-entre-promesses-et-defis)
* *Rentrée 2024 : offensives sur l'IA dans l'éducation:* https://www.snes.edu/article/rentree-2024-offensives-sur-lia-dans-leducation/
Cela n'avance pas, malheureusement avec l'éducation nationale.
Qu'en pensez-vous? Faut-il confier ces formations au secteur privé ?
- Lourdeur administrative- Délais d'adaptation longs- Formation continue parfois insuffisante- Résistance au changement
Avantages :- Plus grande réactivité- Innovation technologique rapide- Méthodes modernes- Capacité d'investissement
- Logique de profit qui peut primer sur la qualité pédagogique- Creusement des inégalités sociales- Perte de contrôle sur les données des élèves- Standardisation de l'enseignement- Dépendance vis-à-vis d'acteurs privés
- Garder le pilotage public de l'éducation- Moderniser l'Éducation nationale de l'intérieur- Développer des partenariats public-privé encadrés- Maintenir une régulation forte sur les contenus et méthodes- S'inspirer des bonnes pratiques du privé tout en préservant les valeurs du service public
- Préserve l'égalité d'accès à l'éducation- Garantisse la qualité pédagogique- Protège les données personnelles- Maintienne l'indépendance du service public- Permette l'innovation tout en gardant un contrôle sur les processus

Plusieurs initiatives ont été mises en place en France pour intégrer l'intelligence artificielle (IA) dans le système éducatif.
Voici quelques programmes et projets notables :


Lu sur le Net : Rentrée 2024 : offensives sur l'IA dans l'éducation
https://www.epi.asso.fr/revue/lu/l2411d.htm
Groupes thématiques numériques – Éducation, numérique et recherche
https://edunumrech.hypotheses.org/category/gtnum
https://edunumrech.hypotheses.org/12941
https://inrialearninglab.github.io/ai4t//fr/
https://www.inria.fr/fr/intelligence-artificielle
https://www.ai4t.eu/deliverables/
https://www.youtube.com/watch?v=9t-fm4liJPw&t=14s
https://edunumrech.hypotheses.org/8350
GAFAM
https://www.microsoft.com/fr-fr/education/products/office?msockid=3285acb143b16ea9246bb9b042c66f1b
https://aws.amazon.com/fr/education/awseducate/
https://about.meta.com/meta-for-education/
https://www.apple.com/fr/education/
https://academy.nvidia.com/en/

https://inrialearninglab.github.io/ai4t//fr/index.html MOOC.
SYNDICAT :
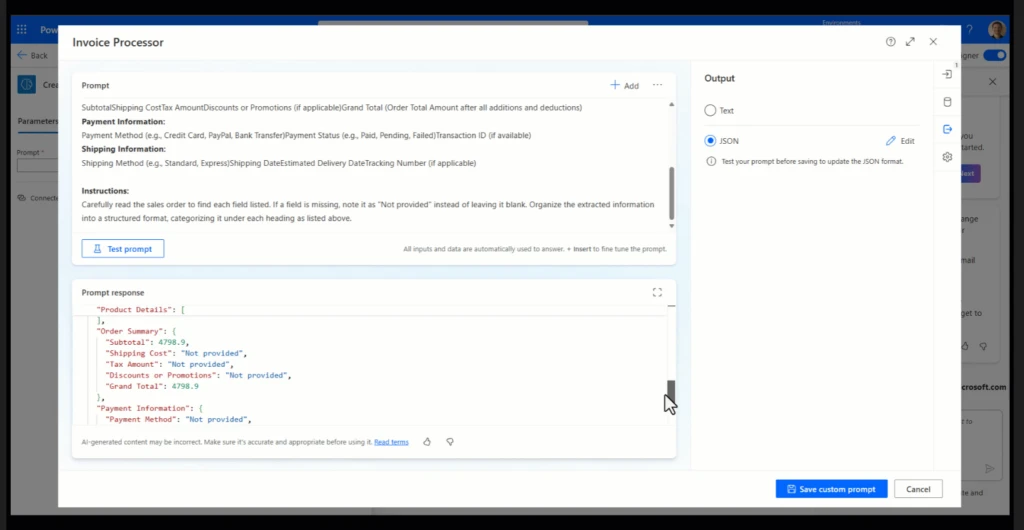
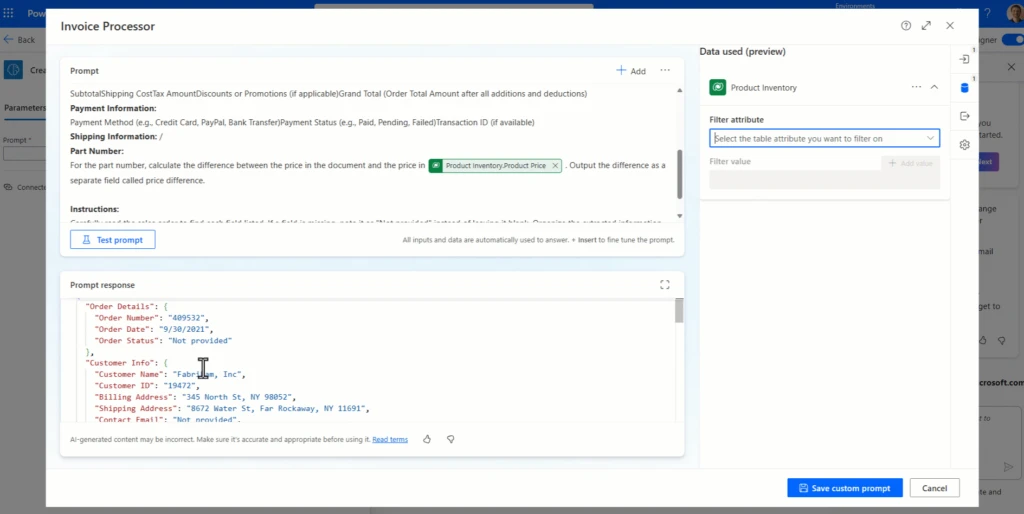
Résumé - Training | Microsoft Learn